Single, readable reference for how our Retrieval‑Augmented Generation (RAG) platform works end‑to‑end at FRB—covering request flow, data/embedding flow, design decisions, and the two codebases that implement it.
In the rapidly evolving world of AI applications, Retrieval Augmented Generation (RAG) has emerged as a powerful pattern for enhancing Large Language Models (LLMs) with up-to-date, domain-specific knowledge. This article walks through building a production-ready RAG ingestion pipeline using AWS services that automatically fetches news from RSS feeds and syncs them with an AWS Bedrock Knowledge Base.
The RAG Architecture Challenge#
When implementing RAG systems, the ingestion pipeline is often overlooked but critically important. A well-designed pipeline should:
- Automatically retrieve fresh content from reliable sources
- Process and structure the content appropriately
- Efficiently sync data with your vector database or knowledge base
- Handle errors gracefully and provide operational visibility
- Scale with your needs while remaining cost-effective
1) Purpose & Scope#
This document explains how user requests flow from the UI → LiteLLM (EKS) → AWS Bedrock (LLM + Knowledge Base), and how content is ingested into S3 and synchronized to Bedrock Knowledge Base (KB) so responses are grounded in our data. It consolidates two projects:
- Project#1 – Python RAG Demos (FastAPI + Streamlit UI) https://gitlab.frb.gov/ai-program/platforms/martin-ai-platform-team/python-rag-demos
- Project#2 – Terraform AWS RAG Data Pipeline (EventBridge → fetcher → syncer) https://gitlab.frb.gov/ai-program/platforms/martin-ai-platform-team/terraform-modules/terraform-aws-rag-data-pipeline

If you have access, click through to inspect the code. If not, request access via normal FRB procedures.
Outcomes of this doc
- Shared mental model for stakeholders and developers.
- Operational clarity for deployment, configuration, and support.
- A baseline for future enhancements (models, embeddings, multi‑tenant KBs, etc.).
2) High‑Level Architecture#
flowchart TD
subgraph UI[User Interface]
A[Streamlit Chatbot]--HTTP-->B
end
subgraph LITE[LiteLLM on EKS]
B[FastAPI / LiteLLM Proxy]
end
subgraph AWS[AWS]
C[Bedrock LLM]
D[Bedrock Knowledge Base]
E[S3: Grounding Documents]
F[EventBridge]
G[Fetcher Lambda]
H[Syncer Lambda]
end
A --> B
B --chat.completions / embeddings--> C
B --retrieve context--> D
D --- E
F --schedule--> G
G --upload docs--> E
G --invoke--> H
H --start ingestion--> D
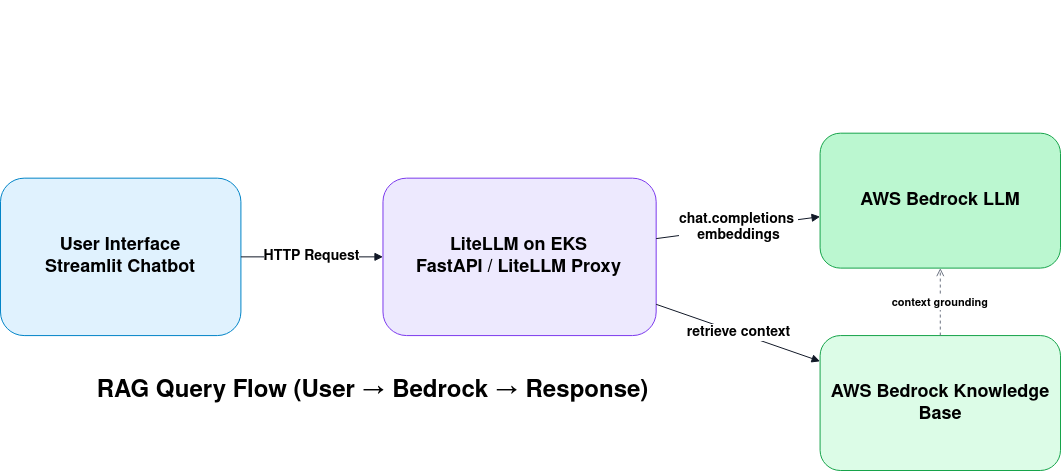
Key idea: UI calls a FastAPI/LiteLLM endpoint hosted on EKS. LiteLLM forwards reasoning to Bedrock LLM and retrieves context via Bedrock KB (which indexes documents living in S3). A separate pipeline (Project#2) keeps S3 and KB fresh by fetching new content and starting ingestion jobs.
3) End‑to‑End Request Flow (UI → LiteLLM → Bedrock)#
- User asks a question in the Streamlit UI (Project#1).
- FastAPI endpoint receives the query. It calls LiteLLM proxy (OpenAI‑compatible) running on EKS.
- LiteLLM constructs the model request and (optionally) calls a retrieval step against Bedrock Knowledge Base to fetch top‑K chunks from S3‑sourced embeddings.
- The LLM generates a grounded answer, with the UI streaming tokens and showing citations mapped to S3 object URIs.
- The UI renders the final answer plus a sources list.
Why LiteLLM? It centralizes model routing, credentials, usage metering, and allows us to alias model names. It exposes FastAPI endpoints and speaks the popular OpenAI API schema to reduce client complexity.
4) Data & Embedding Flow (S3 ↔ Bedrock KB)#
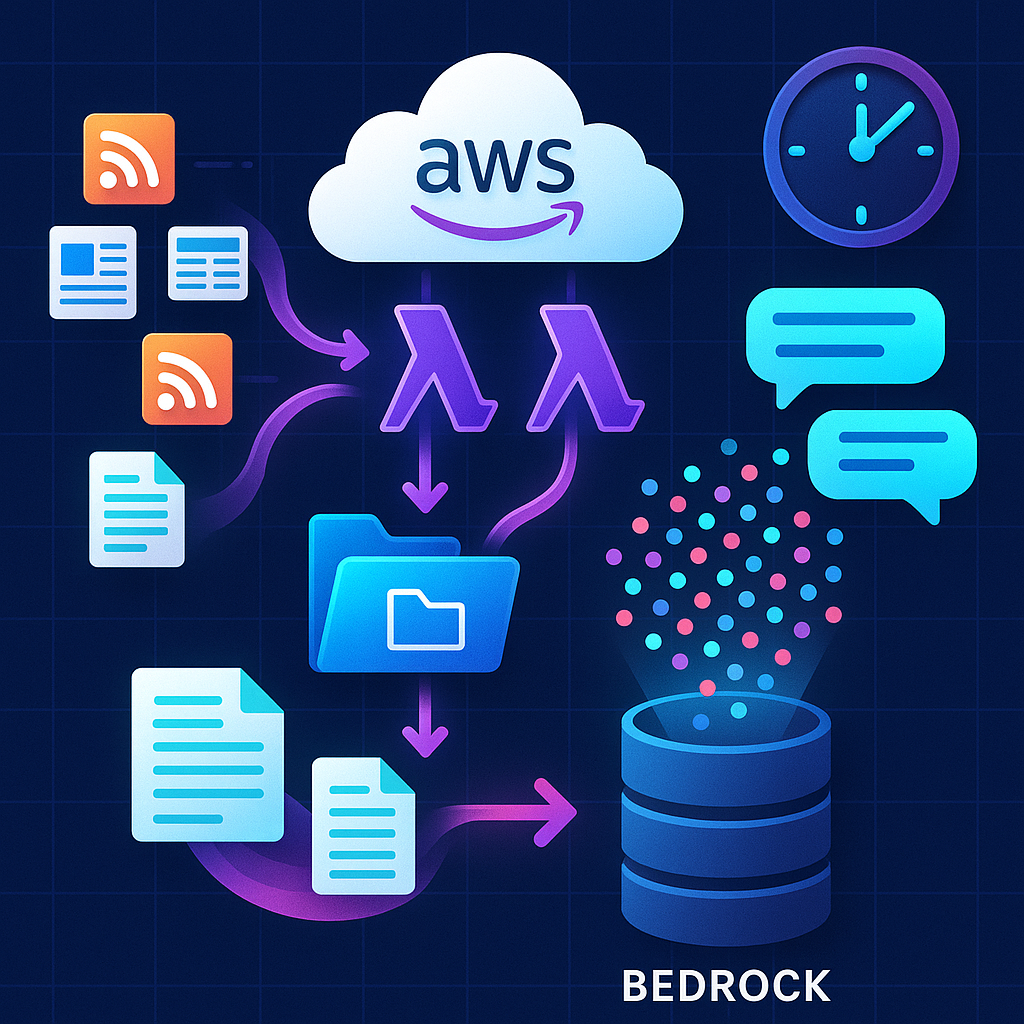
- Fetcher Lambda (Project#2) runs on a schedule via EventBridge (default: every 10 min) and fetches content (e.g., Yahoo RSS articles in the demo).
- Fetcher structures items into JSON, writes them under
s3://<bucket>/<incoming>/<date>/<id>.json, and asynchronously invokes Syncer. - Syncer Lambda (Project#2) starts a Bedrock KB ingestion job (optionally for a specific Data Source) so Bedrock crawls/embeds what changed in S3.
- Bedrock KB updates its index. Subsequent queries see the fresh chunks during retrieval.
Incrementalism: fetcher stores a “last‑run” timestamp (cursor) to only process new items and minimize cost.
5) Components#
5.1 UI & Application (Project#1)#
- Streamlit chatbot UI (
chatbot_ui.py) for interaction and streaming display. - FastAPI backend (
main.py) exposes/document-chat-streamand performs retrieval + prompt assembly with citations. - LiteLLM proxy: deployed separately on EKS; the app points to it via
LITELLM_PROXY_URLand API key. - Bedrock KB client:
bedrock-agent-runtime.retrieve()to fetch top‑K chunks per query.
Local & Containerized Runs
- Conda env (
environment.yml) supports FastAPI + Streamlit. - Dockerfile to containerize the FastAPI server for consistent deploys.
5.2 Ingestion Pipeline (Project#2)#
- EventBridge Rule:
rag_hourly_ingest_eb(name via TF var) triggers fetcher. - Fetcher Lambda: fetches RSS (demo), writes to S3, invokes syncer, updates cursor.
- Syncer Lambda: validates uploaded keys and starts Bedrock KB ingestion.
- Terraform IaC: defines S3, EventBridge, Lambdas, IAM, variables/outputs.
Configurability: All names/IDs via TF vars and Lambda env vars—no hard‑coding.
6) Design Decisions#
- Middleware: LiteLLM on EKS standardizes how clients talk to models, supports multiple providers, and keeps secrets centralized.
- Retrieval: Bedrock Knowledge Base chosen for managed ingestion/embedding and tight integration with S3.
- Separation of concerns: Query‑time serving (Project#1) is isolated from data freshness (Project#2). Each Lambda has a single responsibility.
- Streaming UX: Answers stream to the UI to improve responsiveness and perceived latency.
- Incremental ingestion: Cursor‑based processing avoids re‑ingesting unchanged content.
Alternatives considered (future work):
- Custom vector DB (OpenSearch/KNN, pgvector, Redis) for special search behavior.
- Additional preprocessors (chunking, PII scrubbing, entity extraction) before S3 upload.
7) APIs & Contracts (selected)#
7.1 Chat Endpoint (FastAPI Project#1)#
- Path:
POST /document-chat-stream - Body:
{ query: str, model?: str="claude-v2-instruct", numberOfResults?: int=5 } - Streamed text response. Errors surface as plain text lines.
- Behavior: Retrieves from Bedrock KB, builds a sources‑first prompt with numeric citations, forwards to LiteLLM for completion.
7.2 LiteLLM Proxy (EKS)#
- OpenAI‑compatible endpoints (
/v1/chat/completions, etc.) behind internal ingress. - Auth:
LITELLM_API_KEYheader; model aliases configured in LiteLLM.
7.3 Syncer (Project#2)#
- Input event:
{ uploaded_keys: string[], source: string, timestamp: iso8601 } - Action:
StartIngestionJob(knowledgeBaseId[, dataSourceId]). - Result:
202 Acceptedw/ job id; logs to CloudWatch and optional S3 job record.
8) Deployment, Config & Secrets#
8.1 Config Surfaces#
- Terraform vars (Project#2): region/profile, bucket name/prefix, schedule, KB ids/names, function names, batch size.
- Lambda env vars: bucket/prefix, cursor key, feeds, region, syncer function name, KB ids.
- App env vars (Project#1):
AWS_REGION,BEDROCK_KB_ID,LITELLM_PROXY_URL,LITELLM_API_KEY.
8.2 Environments#
- dev / staging / prod: replicate stacks by var‑files. Buckets and function names are namespaced with the
projectvar.
8.3 Secrets#
- Store keys/tokens in AWS Secrets Manager or Kubernetes secrets. Never commit to git. Use LiteLLM’s master/salt keys for encrypted provider creds.
9) Security & Compliance#
- IAM least privilege: separate roles/policies for fetcher/syncer (S3 read/write, Lambda invoke, Bedrock ingestion).
- Data at rest: S3 SSE enabled (AES256). Versioning enabled.
- Data in transit: TLS for UI → EKS ingress and EKS → AWS.
- Access control: GitLab permissions for repos; EKS RBAC for ops; audit via CloudTrail/CloudWatch.
- PII/Compliance: Add preprocessing stage (redaction/classification) before upload if needed.
10) Observability & Operations#
Logs: CloudWatch for Lambdas; FastAPI/LiteLLM app logs via Kubernetes logging.
Metrics to track: Request latency, token usage, retrieval hit‑rate, ingestion job counts/success rate, S3 object churn.
Alarms: Lambda errors/throttles, ingestion job failures, unusually low retrieval results, EKS pod restarts.
Runbooks:
- Rerun ingestion job on failure.
- Smoke test fetcher via
aws lambda invoke. - Empty
incoming/prefix safely for re‑ingestion.
11) Non‑Functional Requirements (NFRs)#
- Availability: 99.5% for the chat API in business hours.
- Latency (p50/p95): <1.5s / <5s for first token (network + LiteLLM + Bedrock).
- Cost: Keep steady‑state infra under agreed monthly budget; use incremental ingestion.
- Scalability: EKS HPA for LiteLLM; Lambda concurrency limits sized to schedule.
- Portability: Local dev paths (Conda/Docker) must mirror prod configs.
12) Acceptance Criteria#
- UI can stream an answer with numbered citations resolving to S3 URIs.
- Changing S3 content and running the pipeline updates KB; new answers reference fresh content.
- All names/IDs are passed via variables (no hard‑coding) across TF and code.
- One‑click smoke test: manual fetcher invoke uploads ≥1 object and triggers syncer; KB job is Started.
- EKS‑hosted LiteLLM responds to a chat completion using model alias configured centrally.
13) How to Use the Repos#
Project#1 – Python RAG Demos#
- Clone and inspect: https://gitlab.frb.gov/ai-program/platforms/martin-ai-platform-team/python-rag-demos
- Follow
environment.ymland the providedDockerfileto run FastAPI and Streamlit locally or in a container. - Set
BEDROCK_KB_ID,LITELLM_PROXY_URL,LITELLM_API_KEY,AWS_REGION.
Project#2 – Terraform AWS RAG Data Pipeline#
- Clone and inspect: https://gitlab.frb.gov/ai-program/platforms/martin-ai-platform-team/terraform-modules/terraform-aws-rag-data-pipeline
- Provide TF vars for: project, region/profile, event rule name, lambda names, bucket (or auto‑gen), schedule, KB IDs.
- Deploy with
terraform init/plan/apply; smoke test by invoking fetcher and checking S3 + CloudWatch logs.
14) Risks & Mitigations#
- RSS summaries only → Add scrapers or paid APIs for full text; store canonical text in S3.
- Provider limits → Backoff/retries; tune schedule and Lambda concurrency; monitor Bedrock quotas.
- KB drift → Nightly reconciliation job that verifies S3 vs. KB index counts.
- Secrets exposure → Centralize in Secrets Manager / K8s secrets; rotate regularly.
15) Roadmap Ideas#
- Multi‑KB routing by domain; per‑team buckets and data sources.
- Pre‑ingestion transforms: chunking, embeddings‑at‑ingest, PII scrubbing.
- Guardrails: retrieval‑confidence scoring; answerable/unanswerable classification.
- Observability pack: dashboards for retrieval quality and token economics.
16) Glossary#
- RAG: Retrieval‑Augmented Generation—LLM answers grounded by external documents.
- KB: Knowledge Base—Bedrock’s managed index over S3‑hosted content.
- LiteLLM: Middleware proxy exposing OpenAI‑style APIs and routing to model providers.
- EventBridge: AWS scheduler/dispatcher used to trigger Lambdas.
Appendix A: Minimal Config Matrix#
| Component | Key Vars | Example |
|---|---|---|
| FastAPI (Project#1) | AWS_REGION, BEDROCK_KB_ID, LITELLM_PROXY_URL, LITELLM_API_KEY | us-east-1, 8FYOHD0OOA, http://litellm.svc:4000, sk-… |
| EventBridge | eventbridge_rule_name, schedule_expression | rag_hourly_ingest_eb, rate(10 minutes) |
| Fetcher Lambda | BUCKET_NAME, S3_PREFIX_INCOMING, CURSOR_KEY, YAHOO_NEWS_FEEDS | …, incoming/, state/cursor.json, …rss |
| Syncer Lambda | BEDROCK_KB_ID, BEDROCK_DATA_SOURCE_ID | 8FYOHD0OOA, JHA7ZKEA48 |
| Terraform | project, aws_region, bucket_name | kb-demo, us-east-1, auto or fixed |
References