
Let’s build a chatbot that can read your documents and intelligently answer questions about them—even when those documents contain knowledge that the AI model has never seen before. This is the core value of Retrieval-Augmented Generation (RAG): giving a frozen language model access to dynamic, user-specific, or post-cutoff knowledge.
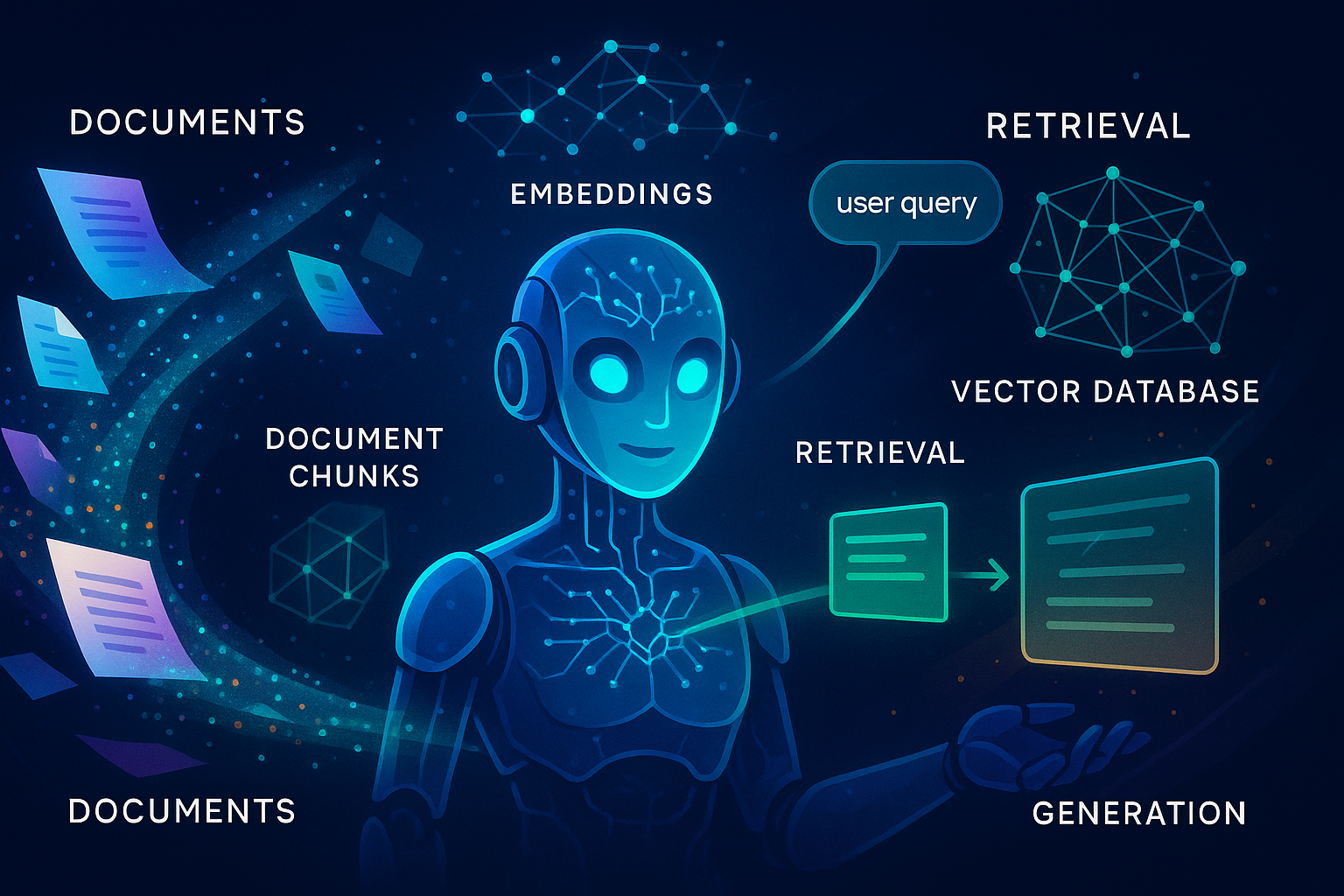
We combine document processing, vector search, and large language models using LangChain’s RAG pipeline. The result: you upload a PDF, ask questions about it in plain English, and get responses grounded in your document’s content—even if that content was authored today and your model was trained last year.
Why RAG Matters: Beyond LLM Knowledge#
You might ask, why not just send the document text directly to the LLM? That works—for short content. But modern PDFs (like lab reports, contracts, transcripts) are often dozens of pages long. LLMs have input token limits. Even worse, they might hallucinate or fall back on general knowledge if no recent information is available.
RAG solves this by splitting, embedding, and searching the document. It feeds only the most relevant chunks into the model, conserving tokens and grounding responses in real, fresh data.
The Office Hour Visit#
Imagine you’re a student visiting your professor during office hours.
- Student A walks in with the whole textbook and says, “Can you help me understand this?”
- Student B walks in with three well-highlighted pages and specific questions circled in red.
Who gets the better, faster, and more focused answer?
Student B. Always.

That’s exactly how RAG helps the LLM:
- Instead of dumping the full PDF into the model (expensive, slow, and sometimes impossible due to size limits),
- RAG picks the most relevant chunks and sends them along with the question.
Why This Matters (Technically)#
| Factor | Student A (Full Book) | Student B (Relevant Chunks via RAG) |
|---|---|---|
| Token Size | Huge (may exceed context window) | Small (focused context only) |
| API Cost | High (billed per token) | Lower (few tokens sent to the LLM) |
| Response Quality | Generic, vague, or off-topic | Grounded, precise, and context-aware |
| Latency | Slower due to large prompt | Faster due to trimmed input |
| Bandwidth | Larger upload/download | Minimal, compact input |
| Model Stability | May truncate or error out | Stable, within limits |
RAG is like being a prepared student. You don’t overwhelm the professor (LLM). You ask clear, relevant questions backed by helpful context.
Step 1: Architecture Overview (Separation of Concerns)#
We use three components:
- DocumentProcessor: Handles PDF parsing, chunking, embedding, and retrieval
- ChatEngine: Talks to the LLM using user input and matched context
- RAGChatbot: Coordinates document ingestion and conversation
This design follows the Separation of Concerns principle: each component has a specific responsibility and doesn’t mix roles. This leads to cleaner code, easier testing, and more modular upgrades.
You can update the document processing logic without touching how the chatbot speaks, and vice versa. That’s the power of clear separation.
Step 2: Processing a PDF#
We use LangChain’s PyPDFLoader to extract text, then RecursiveCharacterTextSplitter to break it into overlapping chunks. This makes it easier to search and retrieve contextually relevant pieces later.
class DocumentProcessor:
def __init__(self):
self.chunk_size = 1000
self.chunk_overlap = 100
self.embedding_model = OpenAIEmbeddings()
self.vectorstore = None
def load_document(self, file_path):
if file_path.endswith('.pdf'):
loader = PyPDFLoader(file_path)
return loader.load()
else:
raise ValueError("Unsupported file format")
def process_document(self, file_path):
docs = self.load_document(file_path)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=self.chunk_size,
chunk_overlap=self.chunk_overlap
)
split_docs = text_splitter.split_documents(docs)
if self.vectorstore is None:
self.vectorstore = FAISS.from_documents(split_docs, self.embedding_model)
else:
self.vectorstore.add_documents(split_docs)
Think of chunking like turning a long article into paragraph cards so you can search just the most relevant pieces later. Embedding is like turning those cards into searchable fingerprints.
Step 3: Ask Questions Like a Human#
When a user types a question, the system:
- Embeds the question (i.e., generates its semantic fingerprint)
- Retrieves the most similar chunks from the document
- Builds a context string
- Sends the question + context to the language model
def send_message(self, message):
relevant_docs = self.document_processor.retrieve_relevant_context(message)
context = ""
for doc in relevant_docs:
source = doc.metadata.get('source', 'unknown')
context += f"Source: {source}\n{doc.page_content}\n\n"
return self.chat_engine.send_message(message, context)
It’s like saying, “Here’s my question, and here are three paragraphs from the document that might help you answer it.”
Step 4: Real-World Use Case — A Medical Example#
Let’s say a user uploads a recent lab result (from July 2025):
medical_lab_result.pdf
“Dear Mr. Clark, your recent blood panel shows elevated creatinine levels, which may suggest impaired kidney function. We recommend a nephrologist referral. Please discontinue NSAIDs until further notice.”
Now the user asks:
“What do abnormal kidney markers usually indicate, and what kind of doctor handles this?”
A frozen LLM trained before 2024 may not know what Mr. Clark’s letter says. But RAG retrieves relevant chunks like:
Chunk:
"...creatinine levels, which may suggest impaired kidney function. We recommend a nephrologist referral."
Because embeddings capture meaning, the following mappings happen under the hood:
- “creatinine levels” ≈ “kidney markers”
- “nephrologist referral” ≈ “what doctor handles this”
The model receives both the question and this exact context. The answer:
“Abnormal kidney markers such as elevated creatinine levels can indicate impaired kidney function. These results are typically evaluated by a nephrologist, a doctor who specializes in kidney care.”
That’s RAG: using fresh, specific documents to fill in gaps the LLM doesn’t know by default.
Step 5: Running the Bot#
# main.py
from rag_chatbot import RAGChatbot
import sys
def start_chatbot(file_name):
chatbot = RAGChatbot()
print(chatbot.upload_document(file_name))
query = "What is this letter about and what do I do next?"
print(f"\nQuestion: {query}")
print(f"Answer: {chatbot.send_message(query)}")
chatbot.reset_all()
if __name__ == "__main__":
start_chatbot(sys.argv[1])
Final Thoughts#
RAG isn’t about replacing LLMs. It’s about augmenting them with domain-specific, up-to-date knowledge. It lets you build assistants that are:
- Fresh (understand new documents)
- Focused (grounded in your data)
- Transparent (can cite exact document chunks)
Whether you’re dealing with medical summaries, legal filings, or internal policies, RAG ensures the chatbot answers based on what you provide—not just what the model once learned.
What’s Next#
In the next post, we’ll explore:
- Filtering by document metadata
- Streaming long responses
- Formatting structured answers (tables, highlights, etc.)
You now have a practical, production-grade base for building reliable document-aware chatbots.