Why APIs speak JSON but you work with dicts
Introduction#
You call an API. It returns data. You access it like response['key']. Simple, right?
But what’s actually happening? Is that JSON or a Python dictionary? Why do some languages call it “marshal” and others call it “serialize”?
This guide answers these questions with practical examples from OpenAI and AWS Bedrock APIs.
What You’ll Learn#
- The Core Difference: Memory structures vs text formats
- Marshal vs Serialize: Why different terms for the same thing
- Real API Examples: OpenAI and AWS Bedrock responses
- When to Convert: Practical patterns for everyday coding
- Common Mistakes: Pitfalls and how to avoid them
Prerequisites#
- Basic Python knowledge (dicts, functions, file I/O)
- Familiarity with APIs (helpful but not required)
- Python 3.7 or higher installed
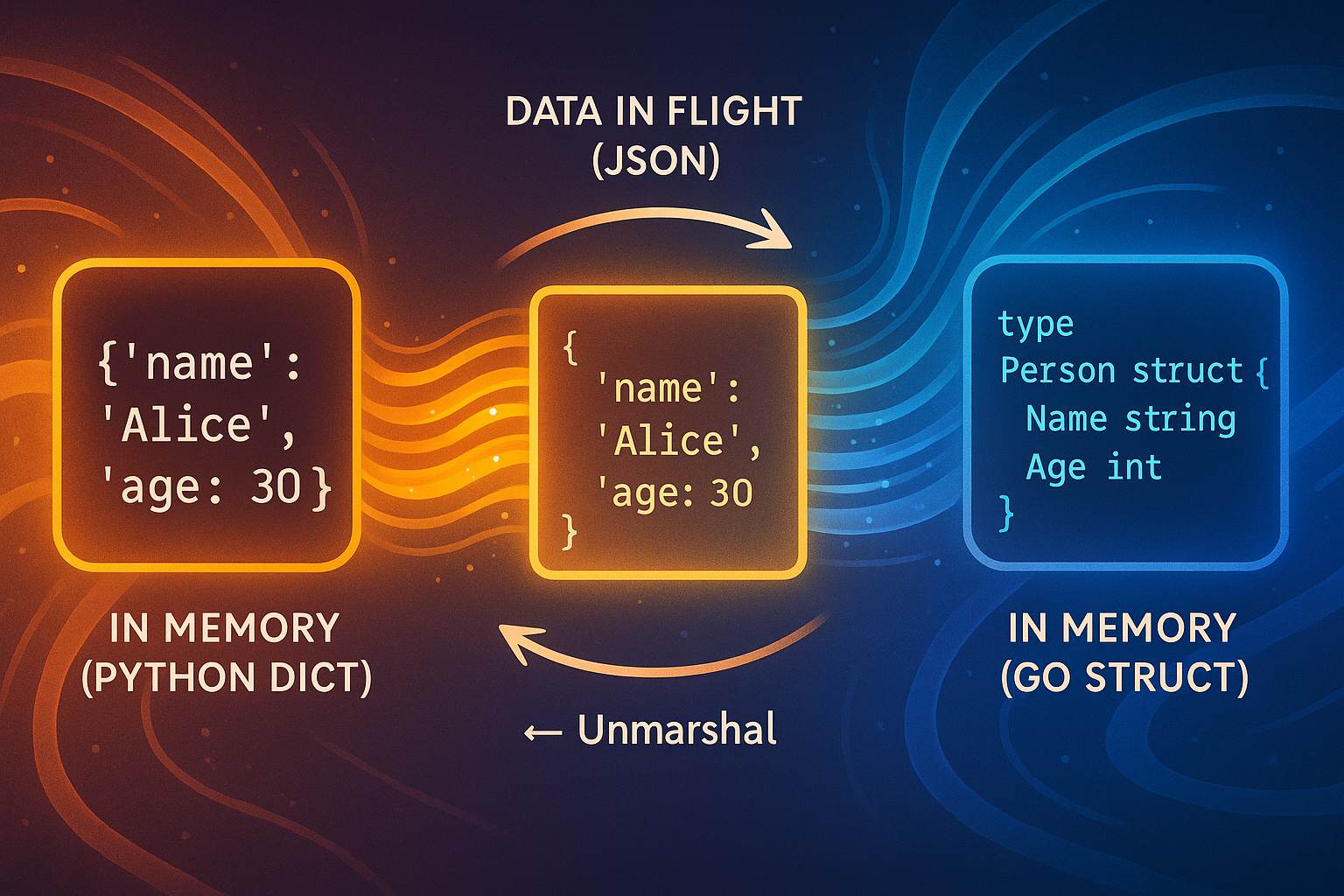
The Simple Truth#
Dict = Data in your computer’s memory
JSON = Data as text (for sending/saving)
That’s it. Everything else is just syntax.
Understanding Dicts#
A Python dictionary lives in memory. You work with it directly:
# This is a dict - exists in memory
user = {
"name": "Alice",
"age": 30,
"active": True
}
# Fast operations
print(user['name']) # Alice
user['age'] = 31 # Modify
user['email'] = "a@b.com" # Add new key
print(type(user)) # <class 'dict'>
Dicts are fast, flexible, and powerful. But they have one problem: they only exist in your program’s memory.
You can’t:
- Email a dict to someone
- Save it to a file (as-is)
- Send it over a network
- Store it in a database
For that, you need JSON.
Understanding JSON#
JSON is text. Plain, readable text:
import json
# Convert dict to JSON text
json_text = json.dumps(user)
print(json_text)
# '{"name": "Alice", "age": 31, "active": true, "email": "a@b.com"}'
print(type(json_text)) # <class 'str'>
Now it’s just a string. You can save it, send it, store it anywhere.
To use it again, convert it back to a dict:
# Convert JSON text back to dict
loaded_user = json.loads(json_text)
print(loaded_user['name']) # Alice
print(type(loaded_user)) # <class 'dict'>
The pattern: Dict → JSON → Transport/Save → JSON → Dict
Real Example: OpenAI API#
When you call OpenAI’s API, this conversion happens automatically:
import openai
import json
# API call
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Explain Python dicts"}]
)
# response is a dict (converted automatically)
print(type(response)) # <class 'dict'>
# Access nested data
message = response['choices'][0]['message']['content']
tokens = response['usage']['total_tokens']
print(f"Answer: {message}")
print(f"Tokens: {tokens}")
What happened:
- OpenAI’s server has data in memory (their internal structure)
- Converts to JSON to send over HTTPS
- Python receives JSON and converts to dict
- You work with the dict
The response structure:
{
"id": "chatcmpl-123",
"choices": [
{
"message": {
"role": "assistant",
"content": "Python dicts are key-value pairs..."
},
"finish_reason": "stop"
}
],
"usage": {
"total_tokens": 47
}
}
Real Example: AWS Bedrock#
Here’s how it works with AWS Bedrock Knowledge Base:
import boto3
import json
# Initialize client
bedrock = boto3.client('bedrock-agent-runtime', region_name='us-east-1')
# Query knowledge base
response = bedrock.retrieve_and_generate(
input={'text': 'What are our security features?'},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': 'YOUR_KB_ID',
'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0'
}
}
)
# response is a dict - work with it
answer = response['output']['text']
print(f"Answer: {answer}")
# Extract source citations
for citation in response.get('citations', []):
for ref in citation.get('retrievedReferences', []):
content = ref['content']['text']
location = ref['location']['s3Location']['uri']
score = ref['metadata']['score']
print(f"\nSource: {location}")
print(f"Relevance: {score:.2f}")
print(f"Content: {content[:100]}...")
# Save for later (convert to JSON)
with open('bedrock_response.json', 'w') as f:
json.dump(response, f, indent=2, default=str)
The response structure:
{
"output": {
"text": "Our platform includes multi-factor authentication..."
},
"citations": [
{
"retrievedReferences": [
{
"content": {"text": "MFA is required for all accounts..."},
"location": {"s3Location": {"uri": "s3://bucket/security.pdf"}},
"metadata": {"score": 0.89}
}
]
}
]
}
Marshal vs Serialize: The Name Game#
Different languages use different terms for the same conversion:
| Language | Memory → Text | Text → Memory | What It’s Called |
|---|---|---|---|
| Python | json.dumps() | json.loads() | Serialize/Deserialize |
| Go | json.Marshal() | json.Unmarshal() | Marshal/Unmarshal |
| Java | writeValue() | readValue() | Serialize/Deserialize |
Go example:
import "encoding/json"
// Marshal (struct to JSON)
jsonBytes, _ := json.Marshal(data)
// Unmarshal (JSON to struct)
var result MyStruct
json.Unmarshal(jsonBytes, &result)
Python equivalent:
import json
# Serialize (dict to JSON)
json_text = json.dumps(data)
# Deserialize (JSON to dict)
result = json.loads(json_text)
Same concept. Different vocabulary. That’s all.
When to Convert#
Dict → JSON (when you need to share)#
import json
data = {"name": "Alice", "score": 95}
# Save to file
with open('data.json', 'w') as f:
json.dump(data, f, indent=2)
# Send in API request
import requests
requests.post('https://api.example.com/data', json=data)
# Log for debugging
print(json.dumps(data, indent=2))
# Store in database as text
db.execute("INSERT INTO logs VALUES (?)", [json.dumps(data)])
JSON → Dict (when you need to use)#
# Read from file
with open('data.json', 'r') as f:
data = json.load(f)
# Parse API response
response_text = '{"status": "success"}'
data = json.loads(response_text)
# Process configuration
config = json.loads(config_string)
Common Mistakes#
Mistake 1: Treating JSON like a dict#
# Wrong - JSON is text, not a dict
json_text = '{"name": "Alice"}'
print(json_text['name']) # TypeError!
# Right - convert first
data = json.loads(json_text)
print(data['name']) # Works!
Mistake 2: Converting repeatedly#
# Inefficient
for i in range(1000):
data = json.loads(json_text) # Converting every time
process(data['value'])
# Efficient
data = json.loads(json_text) # Convert once
for i in range(1000):
process(data['value']) # Use many times
Mistake 3: Non-JSON types#
from datetime import datetime
# Fails
data = {"timestamp": datetime.now()}
json.dumps(data) # TypeError: datetime not JSON serializable
# Works
data = {"timestamp": datetime.now().isoformat()}
json.dumps(data) # Success
Mistake 4: Unsafe nested access#
# Risky - crashes if structure is different
content = response['choices'][0]['message']['content']
# Safer
content = (
response.get('choices', [{}])[0]
.get('message', {})
.get('content', '')
)
Practical Patterns#
Pattern 1: Save and load#
import json
# Save
with open('response.json', 'w') as f:
json.dump(response, f, indent=2)
# Load
with open('response.json', 'r') as f:
response = json.load(f)
Pattern 2: Pretty print for debugging#
print(json.dumps(response, indent=2))
Pattern 3: Handle dates#
from datetime import datetime
import json
data = {
"timestamp": datetime.now(),
"user": "alice"
}
# Convert datetime to string
json.dumps(data, default=str) # Uses str() for non-JSON types
Pattern 4: Group and summarize (Bedrock)#
from collections import defaultdict
def group_chunks_by_document(response):
"""Group retrieved chunks by source document"""
grouped = defaultdict(list)
for citation in response.get('citations', []):
for ref in citation.get('retrievedReferences', []):
uri = ref['location']['s3Location']['uri']
grouped[uri].append({
'content': ref['content']['text'],
'page': ref['metadata'].get('x-amz-bedrock-kb-document-page-number'),
'score': ref['metadata']['score']
})
return dict(grouped)
# Usage
grouped = group_chunks_by_document(response)
for uri, chunks in grouped.items():
filename = uri.split('/')[-1]
print(f"\n{filename}: {len(chunks)} chunks")
for chunk in chunks:
print(f" Page {chunk['page']}: {chunk['content'][:80]}...")
Best Practices#
- Convert once, use many - Don’t repeatedly parse the same JSON
- Use
indent=2for readability - When saving or debugging - Handle missing keys safely - Use
.get()with defaults - Convert non-JSON types - datetime → isoformat(), sets → lists
- Validate structure - Check keys exist before accessing
- Use type hints - Make your code self-documenting
from typing import Dict, Any
import json
def process_api_response(response: Dict[str, Any]) -> str:
"""Extract message from API response safely"""
choices = response.get('choices', [])
if not choices:
return ""
message = choices[0].get('message', {})
return message.get('content', '')
Summary#
The mental model:
- Work with dicts in memory (fast, flexible)
- Convert to JSON for transport/storage (shareable, saveable)
- Marshal/Unmarshal = same as serialize/deserialize = same as dumps/loads
The pattern:
- Receive JSON from API → automatically converted to dict
- Work with dict in your code
- Save/send dict → convert to JSON
- Load/receive JSON → convert back to dict
Key functions:
json.dumps(dict)→ JSON stringjson.loads(string)→ dictjson.dump(dict, file)→ save to filejson.load(file)→ load from file
That’s everything you need to know. No complexity, no confusion.
Questions? Drop a comment. Found this helpful? Share it with someone who’s confused about JSON.
Keep it simple. Keep coding.